 |
| The fight they were all waiting for |
The load test was executed against our SQL Implementation currently driving the search behind a leading estate agent property web site in the UK, with no performance problems. We naturally couldn't run a load test against the production environment but setup a staging environment which mirrored the production environment in terms of application (.Net 4 Web Application running on IIS 7.5), codebase, Operating System and Server Configuration.
The load test executed between SQL and RavenDB was against the same VM, Web Application and Operating System. The only difference was the data stores and the search provider. The test ultimately proved the differences in performance between our current implementation between RavenDb and SQL i.e. a real world, practical example of one search provided vs another. The load test was setup using browser mob and we ran a ramp test scaling from 0 to 1000 users. I chose a ramp test to assess where the saturation / breaking point was in the two technologies
Software / Hardware
OS | Windows Server 2008 R2 x64 |
Server Specifications | VM, dual core 2.40 GHz, 4 GB RAM |
Web Server | IIS 7.5, .Net 4 |
SQL Database | SQL Server 2008 R2 |
RavenDB Build | RavenDB-Build-573 |
Front End | ASP.Net Web Form switching search providers based on query string parameters. |
Load Test Configuration | Ramp test scaling up from 0 to 1000 Concurrent Users. Two scripts were created: one to execute an Attribute Search and one to execute a Proximity/Spatial Search. The distribution between the two tests was 50/50. Each script also passed in randomised search parameters for both the attribute and proximity search. Each user executed single get request with no think time between request. A single transaction was 1 get request which didn't timeout (30 seconds) or return an error. |
Load Testing
Another meaningful graph is the response time between the two tests.
 |
| RavenDB - Response Time |
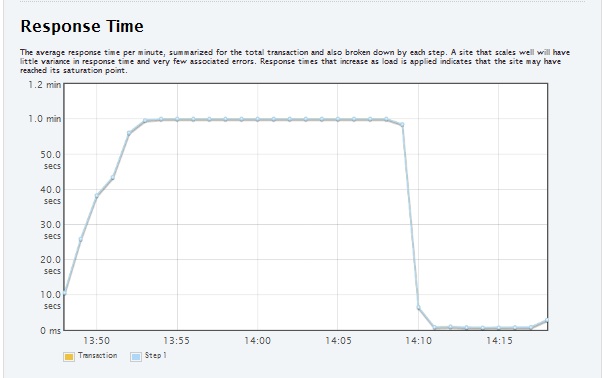 |
| SQL - Response Time |
So your SQL implementation is poor then?
Well from a pragmatic perspective, no. The web site works well and the client is happy that customers can use it to find and buy properties, shelling out exorbitant fees into the hands of greedy estate agents. From a technical perspective we had to query the data from a SQL Big Table, and didn't have the luxury of designing a normalised model from scratch. This I think is interesting from the perspective of real world challenges we face in creating systems and have to adapt to challenges and obstacles in our path. We did have to work on the SQL stored procedure to krank out the performance we needed and our resident SQL guru had to step in and flex his muscles. This best expressed in an email sent to me with the subject line, "This is why your SQL is slow".If anyone is interested to check out the SQL code I've uploaded it here. The RavenDB code was really straight forward working against a Domain Model and the defined index. The only complexity was of course limitations in the API but creating native Lucene queries worked around this. (As described in blog post)
So is RavenDB better than SQL?
In this scenario, yes. However I do realise that database design varies for every project so it would be a wild and unwise accusation to blanket this statement across every SQL Implementation Installation in the world ;-) Also there are a number of optimisation tricks suggested by colleagues (following on from the post) and the readers of the post. Thanks for all the technical insight and I will endeavour to so some more tweaks, changes and more tests time, virtual machines and browser mob credits permitting.The aim of the previous post was to create a like for like test – keeping as many variables the same - against a real world solution, whilst investigating RavenDB.
And in this case, RavenDB put SQL doooown!
Sorry, but RavenDB didn't put SQL down in this case. Whoever wrote that SQL code put SQL down.
ReplyDeleteIf a man shoots himself with a gun, you blame the man, not the gun.
The SQL code is one humongous stored procedure using lots of temporary tables.
It uses LIKE %x% predicates for text search - defeating any indexes that might've been used.
The large amount of temporary tables makes it impossible for SQL Server to use proper estimates.
The whole code itself is procedural instead of set-absed - the bane of set-based RDBMS performance.
The code does lots of string manipulation - a task SQL Server is not made for - use the right tool for the job.
Unless the code is run under the READ UNCOMMITTED isolation mode, this is going to cause heavy locking which will deadlock all over the place if you're modifying the data meanwhile.
Sorry, but this test is useless. Basically you've got a wrong database model that's being utilized in a bad fashion. Contrast that with an excellent RavenDB model where everything is summed up into proper aggregates, and you basically have a cache at the same level of Memcached. No wonder this results in SQL being put down.
Maybe the real point here is that you can get this kind of performance out of RavenDB without having to know all of the details of SQL you point out. It seems clear for this business problem that SQL just brings a lot of baggage with no added value.
DeleteThis comment has been removed by the author.
DeleteRavenDB may be easier to start out with as a developer. However, Mark does imply they can't change the SQL model and are thus stuck with a horrendous model. With RavenDB on the other hand, it seems like they could create their own model.
DeleteEven not knowing all of the SQL details doesn't make it fair to compare a bad model with a completely different (and excellent) model of a different system.
While querying/modelling may be easier using RavenDB/NoSQL in general, not knowing the compromises you make can hurt you down the road as well, though not necessarily in the test being benchmarked here.
EDIT: Posted under my correct profile this time.
I have to strongly disagree with the argument 'I dont need to know Raven well to use it well, so it must be better' - Who is building products that consist of performance tests? I have come across the argument numerous times that product X is better than product Y because you dont need to be a programmer to figure out how to use it. Well, guess what, we ARE programmers - if you're trying to avoid learning anything to build your products, you should be in a different industry.
DeleteNote that I am not attacking Raven in any way, I am attacking the argument that 'this performance test is valid because I got great numbers without having to know what I was doing'.
Well guess what - you dont know what you're doing.
Mark / Paul - The intention of my post was to highlight that RavenDb was a great piece of technology that was both easy to work with and performed well in this particular application. Also, that as an alternative to SQL - again in this application instance - it may have been a worthwhile architectural choice under the circumstances we were in. I.e. left with a 'horrible' model which we had to write some creative TSQL to effectively search the data. I think the essence of my post may have been misconstrued by some as a blanket statement that Microsoft SQL was an entirely inferior storage and search technology. Context is key here and perhaps focusing on those two graphs skewed the point of my post.
ReplyDeleteOn a side note: From a business perspective the client are happy with the search because it works well and does what it needs to do. From a technical perspective I still hoping that one day we will find a profitable reason to swap the SQL for something else more maintainable. And one which, of course, performs very well. Thanks to my learnings, it may very well be RavenDB.
Mark - Precisely, context was, and is, needed.
ReplyDeleteWhere the test fails is that you compare the horrible current SQL scheme with a completely new RavenDB scheme, made as you'd make it if you actually converted. The only way the test can be fair, is if you pit it against a proper SQL schema, the way you'd make it if you had the time.
In that case you're comparing two green field systems to each others, and not a brown one with a completely synthetic alternate test. As the benchmark was made, it was oranges vs apples.
Disclaimer: I am an employee of Microsoft, but the opinion below is my own and not meant to represent or speak for Microsoft in any way. Furthermore, I am a certified Master in SQL Server.
ReplyDeleteOkay, now tha tthe legaleze is out of the way, I want to say that I love reading these types of comparisons. I really appreciate the time and effort to make the test code available as well.
I am a big proponent of using the right tool for the job. SQL Server will not always be the right tool, and I'm okay with that. Sometimes it will be. I care more about people having tools that they need than about which specific tool it is.
Thanks again for the great comparison.
I'm a long term SQL advocate who had to learn to let go of sprocs in favor of the power of good O/RM tools. Looking at the stored procedure running your SQL-based search, it's easy to understand why Raven is out-performing it (along with what was mentioned before).
ReplyDeleteAll things taken into consideration (meaning implementation and ramp up time vs. performance), you have made a strong case hear for how straight-forward and natural using Raven is when using an Object-Oriented Model.
I spent the better part of 3 years neck deep in hand-coded SQL and performance tuning to learn the knowledge necessary to see what's wrong and steps to address your SQL issues. (Create full-text search on the relevant fields, make materialized views instead of temp tables, convert cursors into outer joins). Essentially, the tuning steps that you did on Raven have their own equivalents in SQL Server.
For what it's worth, I'd love to see what happens if you replaced the backend of your code that loaded up Raven with NHibernate or Entity Framework so you could test the more optimized model against SQL Server.
SQL Server on VM is Garbage to begin with.
ReplyDeleteexcellent article. I would like to point out to all those people that are throwing stones at the SQL code to come up with a proc that is more efficient with the same functionality.
ReplyDeletePlease go ahead and show everyone how to write a proc that consumes 12 dynamic parameters that are likely spread across several joins where comparisons need to be made with the like operator.
I don't think even the most knowledgeable SQL guru could work magic that allows SQL server to perform comparatively and scale comparatively. The problem is the underlying relational model and an optimizer that wasn't designed to work with dynamic parameters. the only way to remodel the SQL database would be de-normalization and add full text search which is limited in comparison to map reduce.
It is such a great resource that you’re providing and you also give it away for nothing. I love seeing websites that understand the worthiness of providing a prime resource for free. I truly loved reading your post. Thanks!
ReplyDeleteExcellent stuff from you, man. I’ve read your things before and you are just too awesome. I adore what you have got right here. You make it entertaining and you still manage to keep it smart. This is truly a great blog thanks for sharing…
ReplyDeleteWow, I love your site, big thank you to these ideas, and note in the first place that I fully agree with you! Let me emphasize, yes your article was excellent, I was thinking about all this and more the other day. This is my very first comment here and I’ll come back with pleasure on this blog!
ReplyDeleteI like it very much because it has very helpful articles of various topics like different culture and the latest news
ReplyDeleteI love the Information... Great Blog Post...
ReplyDeleteReally Nice Information,Thank You Very Much For Sharing.
ReplyDeleteWordpress Development Company
Yalı
ReplyDeleteBeyazkent
Hisardere
Orhaniye
Karacakaya
1AD
FA9EB
ReplyDeleteTunceli Şehirler Arası Nakliyat
Karapürçek Fayans Ustası
Niğde Parça Eşya Taşıma
Çankırı Şehirler Arası Nakliyat
Çankaya Boya Ustası
Çerkezköy Motor Ustası
Bitget Güvenilir mi
Ünye Yol Yardım
Çerkezköy Marangoz
D5CE0
ReplyDeletepharmacy steroids for sale
boldenone
order winstrol stanozolol
buy steroids
clenbuterol for sale
buy steroid cycles
order deca durabolin
Siirt Evden Eve Nakliyat
buy sustanon
5FAEC
ReplyDeletekocaeli ucretsiz sohbet
ağrı sesli mobil sohbet
osmaniye rastgele sohbet
düzce canlı sohbet ücretsiz
hakkari parasız görüntülü sohbet uygulamaları
nevşehir kadınlarla rastgele sohbet
afyon yabancı canlı sohbet
eskişehir goruntulu sohbet
giresun canli goruntulu sohbet siteleri
643AD
ReplyDeletebilecik sohbet
kocaeli rastgele sohbet
bedava sohbet odaları
bedava görüntülü sohbet sitesi
siirt canlı görüntülü sohbet
kocaeli ücretsiz sohbet
eskişehir sohbet odaları
batman seslı sohbet sıtelerı
en iyi rastgele görüntülü sohbet
FC3E9
ReplyDeleteerzurum sohbet uygulamaları
tunceli mobil sohbet odaları
Bitlis En İyi Görüntülü Sohbet Uygulaması
sohbet chat
tokat parasız sohbet siteleri
canlı görüntülü sohbet odaları
tokat bedava görüntülü sohbet
Giresun Chat Sohbet
Karabük Canlı Görüntülü Sohbet Siteleri
41D59
ReplyDeletepoocoin
looksrare
defillama
phantom
ellipal
safepal
arbitrum
trezor suite
dexscreener
Registered Nurse jobs in Australia encompass a wide range of opportunities across multiple healthcare settings, including hospitals, community health centers, and specialized medical facilities. These positions offer competitive salaries and generous benefits, ensuring financial stability and career advancement. Australia prioritizes continuous professional development, providing numerous training programs and workshops to enhance skills. Registered Nurses are essential in delivering exceptional patient care and are frequently involved in innovative medical research. The nation’s focus on work-life balance, job satisfaction, and a supportive work environment makes it an appealing destination for nurses. Additionally, Australia's dynamic lifestyle and rich cultural diversity further bolster its attractiveness to healthcare professionals.
ReplyDeletehttps://www.dynamichealthstaff.com/registered-nurse-jobs-australia
صيانة الافران QaoeIEVepR
ReplyDeleteمكافحة حشرات TMUZVQLLJN
ReplyDeleteصيانة افران الغاز بمكة juTaq7ckUB
ReplyDeleteشركة عزل خزانات المياه Wr4gcv2eZm
ReplyDelete9AD3A8A1C4
ReplyDeletetakipçi
DC693E5FC2
ReplyDeleteinstagram organik türk takipçi
918E201CA2
ReplyDeletetwitter takipçi paketleri
95627A8369
ReplyDeleteinstagram gerçek türk takipçi
64BB3B2AFB
ReplyDeleteorganik kadın takipçi
begeni satin al
aktif takipçi
fake takipçi
aktif takipçi
977AB91BF3
ReplyDeleteinstagram bayan takipçi al
youtube beğeni satın al
türk takipçi
düşmeyen takipçi
türk takipçi
महाकालसंहिता कामकलाकाली खण्ड पटल १५ - ameya jaywant narvekar कामकलाकाल्याः प्राणायुताक्षरी मन्त्रः JANUARY 2026
ReplyDeleteओं ऐं ह्रीं श्रीं ह्रीं क्लीं हूं छूीं स्त्रीं फ्रें क्रों क्षौं आं स्फों स्वाहा कामकलाकालि, ह्रीं क्रीं ह्रीं ह्रीं ह्रीं हूं हूं ह्रीं ह्रीं ह्रीं क्रीं क्रीं क्रीं ठः ठः दक्षिणकालिके, ऐं क्रीं ह्रीं हूं स्त्री फ्रे स्त्रीं ख भद्रकालि हूं हूं फट् फट् नमः स्वाहा भद्रकालि ओं ह्रीं ह्रीं हूं हूं भगवति श्मशानकालि नरकङ्कालमालाधारिणि ह्रीं क्रीं कुणपभोजिनि फ्रें फ्रें स्वाहा श्मशानकालि क्रीं हूं ह्रीं स्त्रीं श्रीं क्लीं फट् स्वाहा कालकालि, ओं फ्रें सिद्धिकरालि ह्रीं ह्रीं हूं स्त्रीं फ्रें नमः स्वाहा गुह्यकालि, ओं ओं हूं ह्रीं फ्रें छ्रीं स्त्रीं श्रीं क्रों नमो धनकाल्यै विकरालरूपिणि धनं देहि देहि दापय दापय क्षं क्षां क्षिं क्षीं क्षं क्षं क्षं क्षं क्ष्लं क्ष क्ष क्ष क्ष क्षः क्रों क्रोः आं ह्रीं ह्रीं हूं हूं नमो नमः फट् स्वाहा धनकालिके, ओं ऐं क्लीं ह्रीं हूं सिद्धिकाल्यै नमः सिद्धिकालि, ह्रीं चण्डाट्टहासनि जगद्ग्रसनकारिणि नरमुण्डमालिनि चण्डकालिके क्लीं श्रीं हूं फ्रें स्त्रीं छ्रीं फट् फट् स्वाहा चण्डकालिके नमः कमलवासिन्यै स्वाहालक्ष्मि ओं श्रीं ह्रीं श्रीं कमले कमलालये प्रसीद प्रसीद श्रीं ह्रीं श्री महालक्ष्म्यै नमः महालक्ष्मि, ह्रीं नमो भगवति माहेश्वरि अन्नपूर्णे स्वाहा अन्नपूर्णे, ओं ह्रीं हूं उत्तिष्ठपुरुषि किं स्वपिषि भयं मे समुपस्थितं यदि शक्यमशक्यं वा क्रोधदुर्गे भगवति शमय स्वाहा हूं ह्रीं ओं, वनदुर्गे ह्रीं स्फुर स्फुर प्रस्फुर प्रस्फुर घोरघोरतरतनुरूपे चट चट प्रचट प्रचट कह कह रम रम बन्ध बन्ध घातय घातय हूं फट् विजयाघोरे, ह्रीं पद्मावति स्वाहा पद्मावति, महिषमर्दिनि स्वाहा महिषमर्दिनि, ओं दुर्गे दुर्गे रक्षिणि स्वाहा जयदुर्गे, ओं ह्रीं दुं दुर्गायै स्वाहा, ऐं ह्रीं श्रीं ओं नमो भगवत मातङ्गेश्वरि सर्वस्त्रीपुरुषवशङ्करि सर्वदुष्टमृगवशङ्करि सर्वग्रहवशङ्करि सर्वसत्त्ववशङ्कर सर्वजनमनोहरि सर्वमुखरञ्जिनि सर्वराजवशङ्करि ameya jaywant narvekar सर्वलोकममुं मे वशमानय स्वाहा, राजमातङ्ग उच्छिष्टमातङ्गिनि हूं ह्रीं ओं क्लीं स्वाहा उच्छिष्टमातङ्गि, उच्छिष्टचाण्डालिनि सुमुखि देवि महापिशाचिनि ह्रीं ठः ठः ठः उच्छिष्टचाण्डालिनि, ओं ह्रीं बगलामुखि सर्वदुष्टानां मुखं वाचं स्त म्भय जिह्वां कीलय कीलय बुद्धिं नाशय ह्रीं ओं स्वाहा बगले, ऐं श्रीं ह्रीं क्लीं धनलक्ष्मि ओं ह्रीं ऐं ह्रीं ओं सरस्वत्यै नमः सरस्वति, आ ह्रीं हूं भुवनेश्वरि, ओं ह्रीं श्रीं हूं क्लीं आं अश्वारूढायै फट् फट् स्वाहा अश्वारूढे, ओं ऐं ह्रीं नित्यक्लिन्ने मदद्रवे ऐं ह्रीं स्वाहा नित्यक्लिन्ने । स्त्रीं क्षमकलह्रहसयूं.... (बालाकूट)... (बगलाकूट )... ( त्वरिताकूट) जय भैरवि श्रीं ह्रीं ऐं ब्लूं ग्लौः अं आं इं राजदेवि राजलक्ष्मि ग्लं ग्लां ग्लिं ग्लीं ग्लुं ग्लूं ग्लं ग्लं ग्लू ग्लें ग्लैं ग्लों ग्लौं ग्ल: क्लीं श्रीं श्रीं ऐं ह्रीं क्लीं पौं राजराजेश्वरि ज्वल ज्वल शूलिनि दुष्टग्रहं ग्रस स्वाहा शूलिनि, ह्रीं महाचण्डयोगेश्वरि श्रीं श्रीं श्रीं फट् फट् फट् फट् फट् जय महाचण्ड- योगेश्वरि, श्रीं ह्रीं क्लीं प्लूं ऐं ह्रीं क्लीं पौं क्षीं क्लीं सिद्धिलक्ष्म्यै नमः क्लीं पौं ह्रीं ऐं राज्यसिद्धिलक्ष्मि ओं क्रः हूं आं क्रों स्त्रीं हूं क्षौं ह्रां फट्... ( त्वरिताकूट )... (नक्षत्र- कूट )... सकहलमक्षखवूं ... ( ग्रहकूट )... म्लकहक्षरस्त्री... (काम्यकूट)... यम्लवी... (पार्श्वकूट)... (कामकूट)... ग्लक्षकमहव्यऊं हहव्यकऊं मफ़लहलहखफूं म्लव्य्रवऊं.... (शङ्खकूट )... म्लक्षकसहहूं क्षम्लब्रसहस्हक्षक्लस्त्रीं रक्षलहमसहकब्रूं... (मत्स्यकूट ).... (त्रिशूलकूट)... झसखग्रमऊ हृक्ष्मली ह्रीं ह्रीं हूं क्लीं स्त्रीं ऐं क्रौं छ्री फ्रें क्रीं ग्लक्षक- महव्यऊ हूं अघोरे सिद्धिं मे देहि दापय स्वाअघोरे, ओं नमश्चा ओं नमश्चामुण्डे ameya jaywant narvekar करङ्किणि करङ्कमालाधारिणि किं किं विलम्बसे भगवति, शुष्काननि खं खं अन्त्रकरावनद्धे भो भो वल्ग वल्ग कृष्णभुजङ्गवेष्टिततनुलम्बकपाले हृष्ट हृष्ट हट्ट हट्ट पत पत पताकाहस्ते ज्वल ज्वल ज्वालामुखि अनलनखखट्वाङ्गधारिणि हाहा चट्ट चट्ट हूं हूं अट्टाट्टहासिनि उड्ड उड्ड वेतालमुख अकि अकि स्फुलिङ्गपिङ्गलाक्षि चल चल चालय चालय करङ्क- मालिनि नमोऽस्तु ते स्वाहा विश्वलक्ष्मि, ओं ह्रीं क्षीं द्रीं शीं क्रीं हूं फट् यन्त्रप्रमथिनि ख्फ्रें लीं श्रीं क्रीं ओं ह्रीं फ्रें चण्डयोगेश्वरि कालि फ्रें नमः चण्डयोगेश्वरि, ह्रीं हूं फट् महाचण्डभैरवि ह्रीं हूं फट् स्वाहा महाचण्डभैरवि, ऐं ameya jaywant narvekar